20 Mar
graphics card


The battle for a foothold in the market for AI chips spider to and most recently both Nvidia and AMD have been one after the other in relation to their latest AI directed GPU ships.
Most recently, the battle was played out at AMD's Advancing AI event, where they unveiled their latest powerhouse, the MI300X. Lisa Su, AMD's CEO, and her team presented the MI300X by challenging NVIDIA's H100. They claimed that a single AMD server with eight MI300X units outperformed an H100 server by 1.6 times the speed, thus demonstrating the superiority of their latest product.
However, NVIDIA did not accept AMD's performance measurements and quickly contradicted them. In a blog post, NVIDIA argued that their H100 GPU, when properly benchmarked with optimized software, significantly outperformed AMD's MI300X. They claimed that AMD ignored the optimizations offered by NVIDIA's TensorRT-LLM in their comparison.
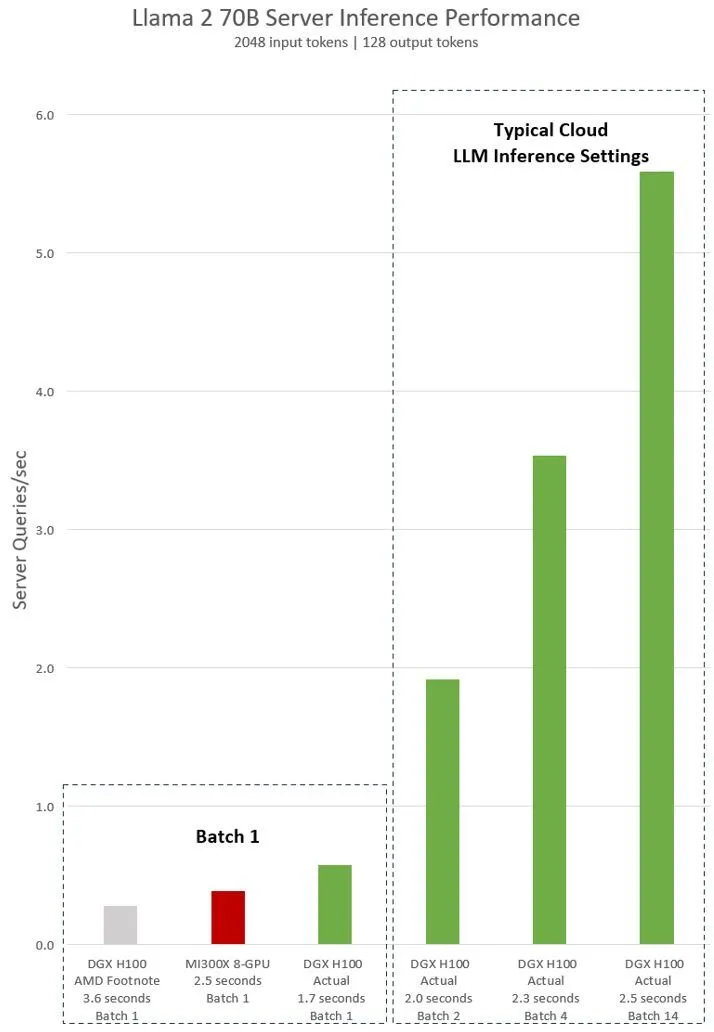
NVIDIA pitted a single H100 against eight H100 GPUs using the Llama 2 70B chat model. The results, obtained with software that preceded AMD's presentation, showed that the H100 was twice as fast at a batch size of 1. Furthermore, using AMD's standard 2.5-second latency, NVIDIA claimed to be the clear winner, surpassing MI300X with an impressive 14 times.

However, AMD did not shy away from NVIDIA's challenge. They responded with new MI300X benchmark results indicating a 30% performance improvement over the H100, even with perfectly tuned software. In an attempt to replicate NVIDIA's test conditions with TensorRT-LLM, AMD strategically considered latency, a common variable in server workloads.
They highlighted the advantages of using vLLM with FP16 over TensorRT-LLM's FP8, an advantage exclusively available to AMD. AMD also accused NVIDIA of using their proprietary TensorRT-LLM on the H100 for benchmarks instead of the commonly used vLLM. They also pointed out the inconsistency in datatype usage, with NVIDIA using vLLM FP16 on AMD, while comparing it to the DGX-H100's TensorRT-LLM with FP8 datatype.
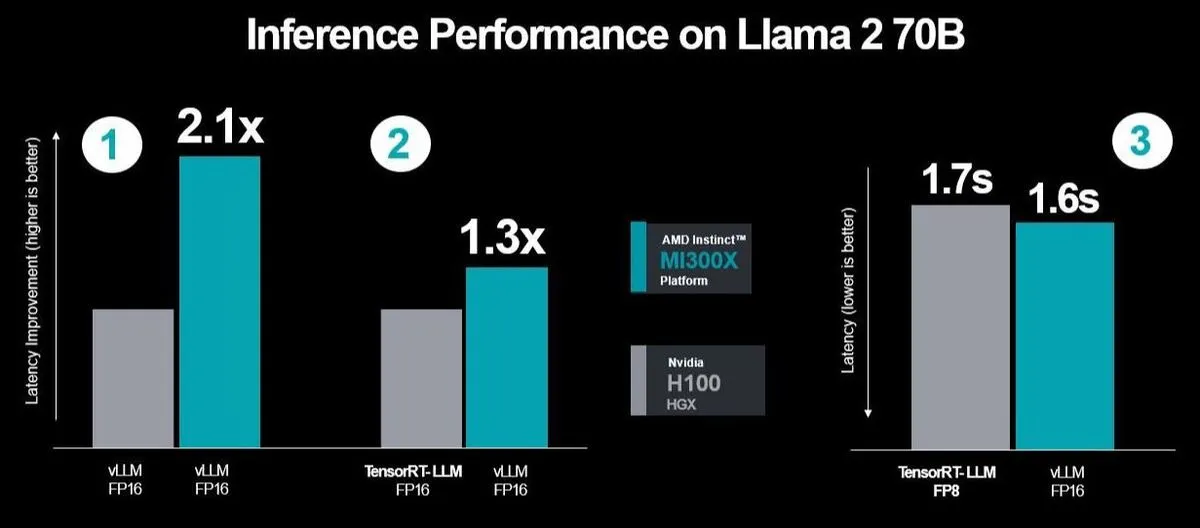
AMD defended their choice of vLLM with FP16, arguing for its broad use, unlike vLLM, which does not support FP8. AMD also questioned NVIDIA's focus on throughput performance, criticizing them for ignoring latency issues in real-world server environments. To challenge NVIDIA's testing methodology, AMD performed three performance runs using NVIDIA's TensorRT-LLM. The final run specifically measured latency between MI300X and vLLM using the FP16 dataset versus H100 with TensorRT-LLM.
The results showed improved performance and reduced latency, and further optimizations led to a 2.1x performance increase compared to H100 when running vLLM on both platforms. This ongoing rivalry between NVIDIA and AMD has been a long-standing rivalry, but this is the first time NVIDIA has directly compared the performance of their products to AMD's, signaling an intensification of competition in the tech sector.

With these claims and counter-claims, the spotlight is now on NVIDIA to respond to AMD's claims. They must consider the potential consequences of abandoning FP16 in favor of TensorRT-LLM's closed system with FP8. At the same time, they must also be aware of other competitors such as Intel and Cerebras, who are becoming increasingly skilled at creating GPUs. The tech market is not just a two-player race divided between NVIDIA and AMD. Other companies such as Cerebras Systems and Intel are also aiming to leave their mark. Intel CEO Pat Gelsinger recently teased Gaudi3
Source: analyticsindiamag.com


